3D Data manipulation
- biapy.data.data_3D_manipulation.load_and_prepare_3D_data(train_path, train_mask_path, cross_val=False, cross_val_nsplits=5, cross_val_fold=1, val_split=0.1, seed=0, shuffle_val=True, crop_shape=(80, 80, 80, 1), y_upscaling=(1, 1, 1), random_crops_in_DA=False, ov=(0, 0, 0), padding=(0, 0, 0), minimum_foreground_perc=-1, reflect_to_complete_shape=False, convert_to_rgb=False, preprocess_cfg=None, is_y_mask=False, preprocess_f=None)[source]
Load train and validation images from the given paths to create 3D data.
- Parameters:
train_path (str) – Path to the training data.
train_mask_path (str) – Path to the training data masks.
cross_val (bool, optional) – Whether to use cross validation or not.
cross_val_nsplits (int, optional) – Number of folds for the cross validation.
cross_val_fold (int, optional) – Number of the fold to be used as validation.
val_split (float, optional) –
%of the train data used as validation (value between0and1).seed (int, optional) – Seed value.
shuffle_val (bool, optional) – Take random training examples to create validation data.
crop_shape (4D tuple) – Shape of the train subvolumes to create. E.g.
(z, y, x, channels).y_upscaling (Tuple of 3 ints, optional) – Upscaling to be done when loading Y data. Use for super-resolution workflow.
random_crops_in_DA (bool, optional) – To advice the method that not preparation of the data must be done, as random subvolumes will be created on DA, and the whole volume will be used for that.
ov (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. The values must be on range
[0, 1), that is,0%or99%of overlap. E. g.(z, y, x).padding (Tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).minimum_foreground_perc (float, optional) – Minimum percetnage of foreground that a sample need to have no not be discarded.
reflect_to_complete_shape (bool, optional) – Wheter to increase the shape of the dimension that have less size than selected patch size padding it with ‘reflect’.
self_supervised_args (dict, optional) – Arguments to create ground truth data for self-supervised workflow.
convert_to_rgb (bool, optional) – In case RGB images are expected, e.g. if
crop_shapechannel is 3, those images that are grayscale are converted into RGB.preprocess_cfg (dict, optional) – Configuration parameters for preprocessing, is necessary in case you want to apply any preprocessing.
is_y_mask (bool, optional) – Whether the data are masks. It is used to control the preprocessing of the data.
preprocess_f (function, optional) – The preprocessing function, is necessary in case you want to apply any preprocessing.
- Returns:
X_train (5D Numpy array) – Train images. E.g.
(num_of_images, z, y, x, channels).Y_train (5D Numpy array) – Train images’ mask. E.g.
(num_of_images, z, y, x, channels).X_val (5D Numpy array, optional) – Validation images (
val_split > 0). E.g.(num_of_images, z, y, x, channels).Y_val (5D Numpy array, optional) – Validation images’ mask (
val_split > 0). E.g.(num_of_images, z, y, x, channels).filenames (List of str) – Loaded train filenames.
Examples
# EXAMPLE 1 # Case where we need to load the data and creating a validation split train_path = "data/train/x" train_mask_path = "data/train/y" # Train data is (15, 91, 1024, 1024) where (number_of_images, z, y, x), so each image shape should be this: img_train_shape = (91, 1024, 1024, 1) # 3D subvolume shape needed train_3d_shape = (40, 256, 256, 1) X_train, Y_train, X_val, Y_val, filenames = load_and_prepare_3D_data_v2(train_path, train_mask_path, train_3d_shape, val_split=0.1, shuffle_val=True, ov=(0,0,0)) # The function will print the shapes of the generated arrays. In this example: # *** Loaded train data shape is: (315, 40, 256, 256, 1) # *** Loaded train mask shape is: (315, 40, 256, 256, 1) # *** Loaded validation data shape is: (35, 40, 256, 256, 1) # *** Loaded validation mask shape is: (35, 40, 256, 256, 1) #
- biapy.data.data_3D_manipulation.load_and_prepare_3D_efficient_format_data(train_path, train_mask_path, input_img_axes, input_mask_axes=None, cross_val=False, cross_val_nsplits=5, cross_val_fold=1, val_split=0.1, seed=0, shuffle_val=True, crop_shape=(80, 80, 80, 1), y_upscaling=(1, 1, 1), ov=(0, 0, 0), padding=(0, 0, 0), minimum_foreground_perc=-1)[source]
Load train and validation images from the given paths to create 3D data.
- Parameters:
train_path (str) – Path to the training data.
train_mask_path (str) – Path to the training data masks.
input_img_axes (str) – Order of axes of the data in
train_path. One between [‘TZCYX’, ‘TZYXC’, ‘ZCYX’, ‘ZYXC’].input_mask_axes (str, optional) – Order of axes of the data in
train_mask_path. One between [‘TZCYX’, ‘TZYXC’, ‘ZCYX’, ‘ZYXC’].cross_val (bool, optional) – Whether to use cross validation or not.
cross_val_nsplits (int, optional) – Number of folds for the cross validation.
cross_val_fold (int, optional) – Number of the fold to be used as validation.
val_split (float, optional) –
%of the train data used as validation (value between0and1).seed (int, optional) – Seed value.
shuffle_val (bool, optional) – Take random training examples to create validation data.
crop_shape (4D tuple) – Shape of the train subvolumes to create. E.g.
(z, y, x, channels).y_upscaling (Tuple of 3 ints, optional) – Upscaling to be done when loading Y data. Use for super-resolution workflow.
ov (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. The values must be on range
[0, 1), that is,0%or99%of overlap. E. g.(z, y, x).padding (Tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).minimum_foreground_perc (float, optional) – Minimum percetnage of foreground that a sample need to have no not be discarded.
- Returns:
X_train (5D Numpy array) – Train images. E.g.
(num_of_images, z, y, x, channels).Y_train (5D Numpy array) – Train images’ mask. E.g.
(num_of_images, z, y, x, channels).X_val (5D Numpy array, optional) – Validation images (
val_split > 0). E.g.(num_of_images, z, y, x, channels).Y_val (5D Numpy array, optional) – Validation images’ mask (
val_split > 0). E.g.(num_of_images, z, y, x, channels).
- biapy.data.data_3D_manipulation.load_3D_efficient_files(data_path, input_axes, crop_shape, overlap, padding, check_channel=True)[source]
Load information of all patches that can be extracted from all the Zarr/H5 samples in
data_path.- Parameters:
data_path (str) – Path to the training data.
input_axes (str) – Order of axes of the data in
data_path. One between [‘TZCYX’, ‘TZYXC’, ‘ZCYX’, ‘ZYXC’].crop_shape (4D tuple) – Shape of the train subvolumes to create. E.g.
(z, y, x, channels).overlap (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. The values must be on range
[0, 1), that is,0%or99%of overlap. E. g.(z, y, x).padding (Tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).check_channel (bool, optional) – Whether to check if the crop_shape channel matches with the loaded images’ one.
- Returns:
data_info (dict) – All patch info that can be extracted from all the Zarr/H5 samples in
data_path.data_info_total_patches (List of ints) – Amount of patches extracted from each sample in
data_path.
- biapy.data.data_3D_manipulation.crop_3D_data_with_overlap(data, vol_shape, data_mask=None, overlap=(0, 0, 0), padding=(0, 0, 0), verbose=True, median_padding=False)[source]
Crop 3D data into smaller volumes with a defined overlap. The opposite function is
merge_3D_data_with_overlap().- Parameters:
data (4D Numpy array) – Data to crop. E.g.
(z, y, x, channels).vol_shape (4D int tuple) – Shape of the volumes to create. E.g.
(z, y, x, channels).data_mask (4D Numpy array, optional) – Data mask to crop. E.g.
(z, y, x, channels).overlap (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. The values must be on range
[0, 1), that is,0%or99%of overlap. E.g.(z, y, x).padding (tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).verbose (bool, optional) – To print information about the crop to be made.
median_padding (bool, optional) – If
Truethe padding value is the median value. IfFalse, the added values are zeroes.
- Returns:
cropped_data (5D Numpy array) – Cropped image data. E.g.
(vol_number, z, y, x, channels).cropped_data_mask (5D Numpy array, optional) – Cropped image data masks. E.g.
(vol_number, z, y, x, channels).
Examples
# EXAMPLE 1 # Following the example introduced in load_and_prepare_3D_data function, the cropping of a volume with shape # (165, 1024, 765) should be done by the following call: X_train = np.ones((165, 768, 1024, 1)) Y_train = np.ones((165, 768, 1024, 1)) X_train, Y_train = crop_3D_data_with_overlap(X_train, (80, 80, 80, 1), data_mask=Y_train, overlap=(0.5,0.5,0.5)) # The function will print the shape of the generated arrays. In this example: # **** New data shape is: (2600, 80, 80, 80, 1)
A visual explanation of the process:
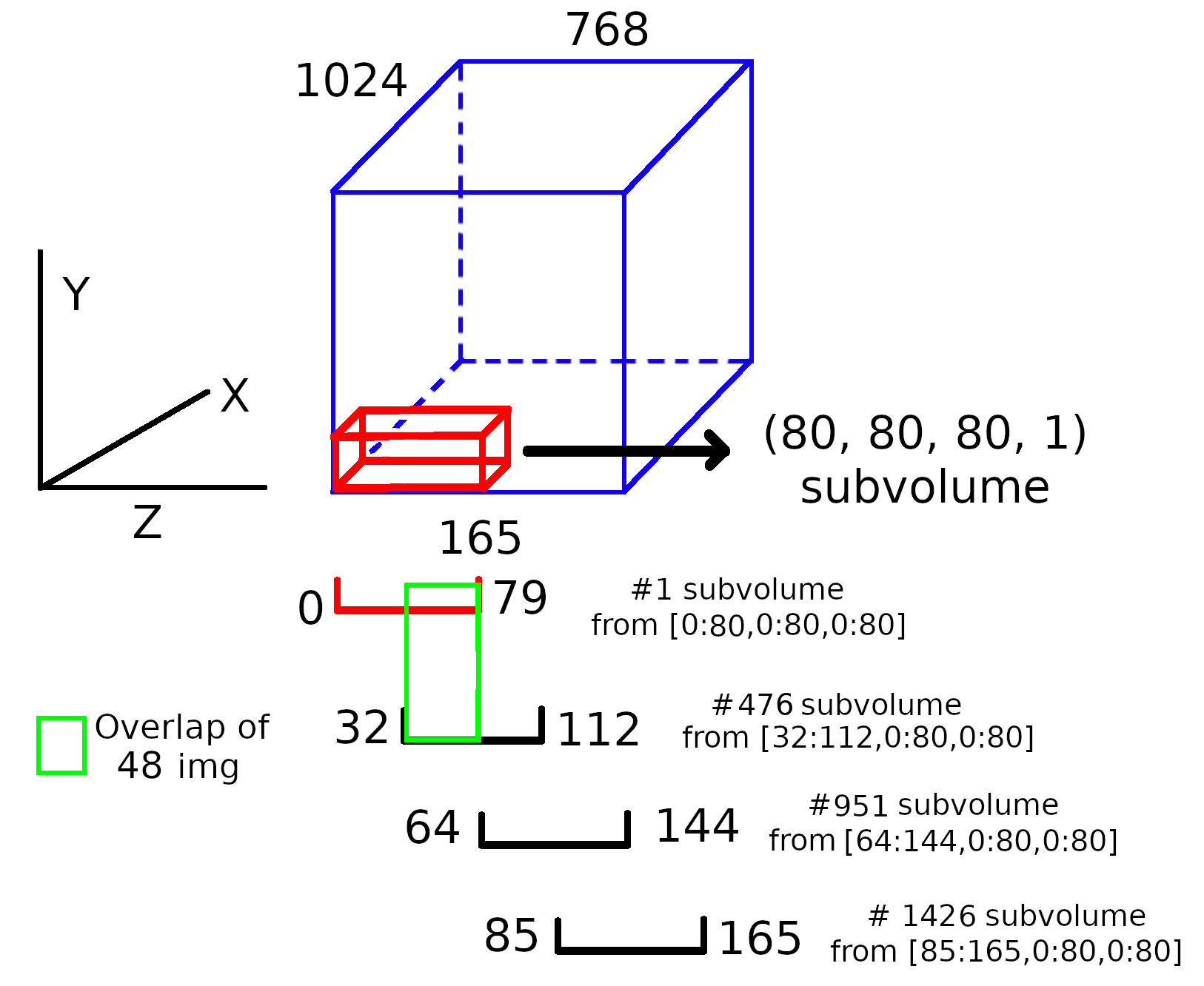
Note: this image do not respect the proportions.
# EXAMPLE 2 # Same data crop but without overlap X_train, Y_train = crop_3D_data_with_overlap(X_train, (80, 80, 80, 1), data_mask=Y_train, overlap=(0,0,0)) # The function will print the shape of the generated arrays. In this example: # **** New data shape is: (390, 80, 80, 80, 1) # # Notice how differs the amount of subvolumes created compared to the first example #EXAMPLE 2 #In the same way, if the addition of (64,64,64) padding is required, the call should be done as shown: X_train, Y_train = crop_3D_data_with_overlap( X_train, (80, 80, 80, 1), data_mask=Y_train, overlap=(0.5,0.5,0.5), padding=(64,64,64))
- biapy.data.data_3D_manipulation.merge_3D_data_with_overlap(data, orig_vol_shape, data_mask=None, overlap=(0, 0, 0), padding=(0, 0, 0), verbose=True)[source]
Merge 3D subvolumes in a 3D volume with a defined overlap.
The opposite function is
crop_3D_data_with_overlap().- Parameters:
data (5D Numpy array) – Data to crop. E.g.
(volume_number, z, y, x, channels).orig_vol_shape (4D int tuple) – Shape of the volumes to create.
data_mask (4D Numpy array, optional) – Data mask to crop. E.g.
(volume_number, z, y, x, channels).overlap (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. Should be the same as used in
crop_3D_data_with_overlap(). The values must be on range[0, 1), that is,0%or99%of overlap. E.g.(z, y, x).padding (tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).verbose (bool, optional) – To print information about the crop to be made.
- Returns:
merged_data (4D Numpy array) – Cropped image data. E.g.
(z, y, x, channels).merged_data_mask (5D Numpy array, optional) – Cropped image data masks. E.g.
(z, y, x, channels).
Examples
# EXAMPLE 1 # Following the example introduced in crop_3D_data_with_overlap function, the merge after the cropping # should be done as follows: X_train = np.ones((165, 768, 1024, 1)) Y_train = np.ones((165, 768, 1024, 1)) X_train, Y_train = crop_3D_data_with_overlap(X_train, (80, 80, 80, 1), data_mask=Y_train, overlap=(0.5,0.5,0.5)) X_train, Y_train = merge_3D_data_with_overlap(X_train, (165, 768, 1024, 1), data_mask=Y_train, overlap=(0.5,0.5,0.5)) # The function will print the shape of the generated arrays. In this example: # **** New data shape is: (165, 768, 1024, 1) # EXAMPLE 2 # In the same way, if no overlap in cropping was selected, the merge call # should be as follows: X_train, Y_train = merge_3D_data_with_overlap(X_train, (165, 768, 1024, 1), data_mask=Y_train, overlap=(0,0,0)) # The function will print the shape of the generated arrays. In this example: # **** New data shape is: (165, 768, 1024, 1) # EXAMPLE 3 # On the contrary, if no overlap in cropping was selected but a padding of shape # (64,64,64) is needed, the merge call should be as follows: X_train, Y_train = merge_3D_data_with_overlap(X_train, (165, 768, 1024, 1), data_mask=Y_train, overlap=(0,0,0), padding=(64,64,64)) # The function will print the shape of the generated arrays. In this example: # **** New data shape is: (165, 768, 1024, 1)
- biapy.data.data_3D_manipulation.extract_3D_patch_with_overlap_yield(data, vol_shape, axis_order, overlap=(0, 0, 0), padding=(0, 0, 0), total_ranks=1, rank=0, return_only_stats=False, verbose=False)[source]
Extract 3D patches into smaller patches with a defined overlap. Is supports multi-GPU inference by setting
total_ranksandrankvariables. Each GPU will process a evenly number of volumes inZaxis. If the number of volumes inZto be yielded are not divisible by the number of GPUs the first GPUs will process one more volume.- Parameters:
data (H5 dataset) – Data to extract patches from. E.g.
(z, y, x, channels).vol_shape (4D int tuple) – Shape of the patches to create. E.g.
(z, y, x, channels).axis_order (str) – Order of axes of
data. One between [‘TZCYX’, ‘TZYXC’, ‘ZCYX’, ‘ZYXC’].overlap (Tuple of 3 floats, optional) – Amount of minimum overlap on x, y and z dimensions. Should be the same as used in
crop_3D_data_with_overlap(). The values must be on range[0, 1), that is,0%or99%of overlap. E.g.(z, y, x).padding (tuple of ints, optional) – Size of padding to be added on each axis
(z, y, x). E.g.(24, 24, 24).total_ranks (int, optional) – Total number of GPUs.
rank (int, optional) – Rank of the current GPU.
return_only_stats (bool, optional) – To just return the crop statistics without yielding any patch. Useful to precalculate how many patches are going to be created before doing it.
verbose (bool, optional) – To print useful information for debugging.
- Yields:
img (4D Numpy array) – Extracted patch from
data. E.g.(z, y, x, channels).real_patch_in_data (Tuple of tuples of ints) – Coordinates of patch of each axis. Needed to reconstruct the entire image. E.g.
((0, 20), (0, 8), (16, 24))means that the yielded patch should be inserted in possition [0:20,0:8,16:24]. This calculate the padding made, so only a portion of the realvol_shapeis used.total_vol (int) – Total number of crops to extract.
z_vol_info (dict, optional) – Information of how the volumes in
Zare inserted into the original data size. E.g.{0: [0, 20], 1: [20, 40], 2: [40, 60], 3: [60, 80], 4: [80, 100]}means that the first volume will be place in[0:20]position, the second will be placed in[20:40]and so on.list_of_vols_in_z (list of list of int, optional) – Volumes in
Zaxis that each GPU will process. E.g.[[0, 1, 2], [3, 4]]means that the first GPU will process volumes0,1and2(3in total) whereas the second GPU will process volumes3and4.
- biapy.data.data_3D_manipulation.load_3d_data_classification(data_dir, patch_shape, convert_to_rgb=False, expected_classes=None, cross_val=False, cross_val_nsplits=5, cross_val_fold=1, val_split=0.1, seed=0, shuffle_val=True)[source]
Load 3D data to train classification methods.
- Parameters:
data_dir (str) – Path to the training data.
patch_shape (Tuple of ints) – Shape of the patch. E.g.
(z, y, x, channels).convert_to_rgb (bool, optional) – In case RGB images are expected, e.g. if
crop_shapechannel is 3, those images that are grayscale are converted into RGB.expected_classes (int, optional) – Expected number of classes to be loaded.
cross_val (bool, optional) – Whether to use cross validation or not.
cross_val_nsplits (int, optional) – Number of folds for the cross validation.
cross_val_fold (int, optional) – Number of the fold to be used as validation.
val_split (float, optional) – % of the train data used as validation (value between
0and1).seed (int, optional) – Seed value.
shuffle_val (bool, optional) – Take random training examples to create validation data.
- Returns:
X_data (5D Numpy array) – Train/test images. E.g.
(num_of_images, z, y, x, channels).Y_data (1D Numpy array) – Train/test images’ classes. E.g.
(num_of_images).X_val (4D Numpy array, optional) – Validation images. E.g.
(num_of_images, z, y, x, channels).Y_val (1D Numpy array, optional) – Validation images’ classes. E.g.
(num_of_images).all_ids (List of str) – Loaded data filenames.
val_index (List of ints) – Indexes of the samples beloging to the validation.