FAQ & Troubleshooting
The Image.sc Forum is the main discussion channel for BiaPy, hence we recommend to use it for any question or curiosity related to it. Use a tag such as biapy so we can go through your questions. Try to find out if the issue you are having has already been discussed or solved by other people. If not, feel free to create a new topic (please provide a clear and concise description to understand and ideally reproduce the issue you’re having).
Frequently asked questions
Installation
When I try to open the BiaPy application In macOS, I get the following error: “BiaPy-macOS” can’t be opened because Apple cannot check it for malicious software.
In some versions of macOS, you might get a security error when trying to execute the BiaPy application for the first time:
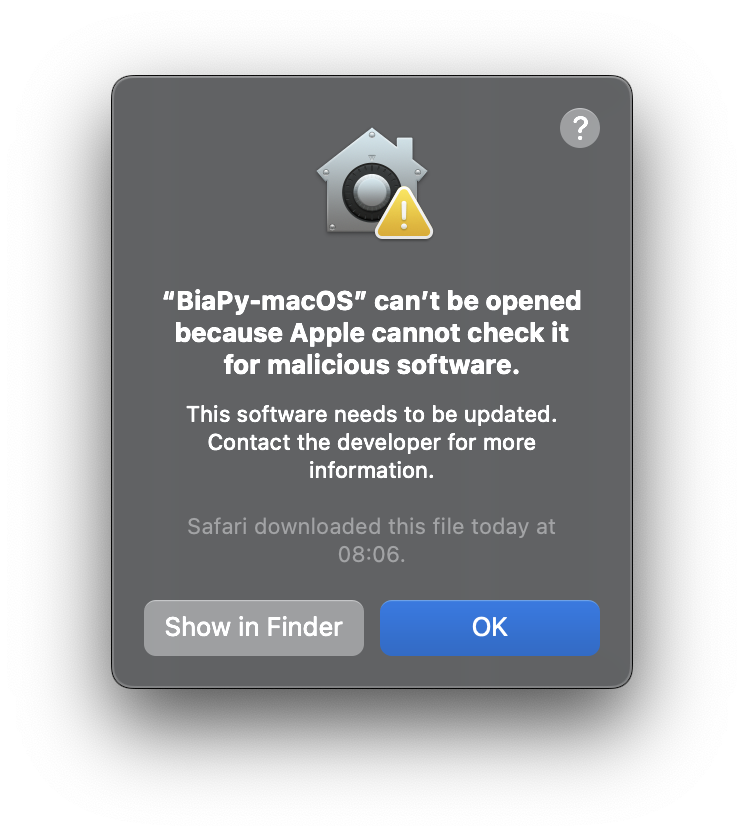
This is a known issue that can be easily bypassed by following a few simple steps depending on the macOS version. For instance, in macOS Sequoia 15 the process is as follows:
On your Mac, choose Apple menu > System Settings, then click Privacy & Security in the sidebar. (You may need to scroll down.)
Go to Security, then you’ll see a message indicating that BiaPy-macOS was blocked:

Click Open Anyway.
This button is available for about an hour after you try to open the app.
Enter your login password, then click OK.
A new window will appear similar to the first one, then click Open.
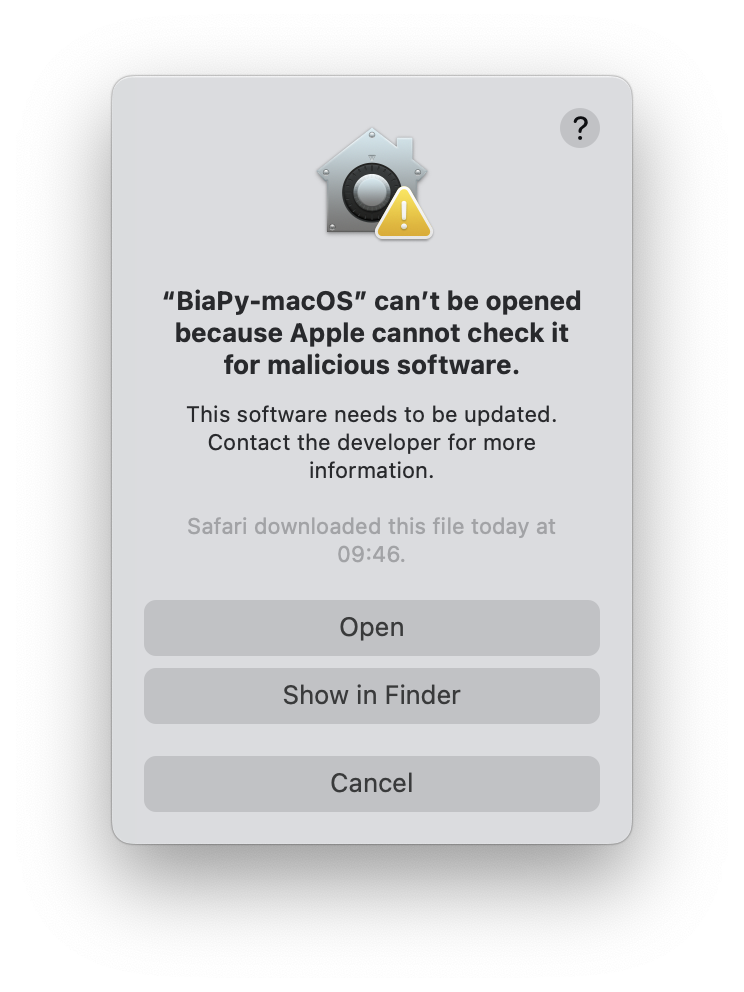
After this, you should be able to open BiaPy normally by simply double-clicking on its app.
If double-clicking the BiaPy binary doesn’t initiate the program, attempt starting it via the terminal to display any potential errors. For Linux users encountering a glibc error (something like
version `GLIBC_2.34' not found), particularly on Ubuntu20.04, you can try the following:sudo apt update sudo apt install libc6
If updating the glibc library to the necessary version (
2.33) for starting the GUI is unsuccessful, you should consider upgrading to Ubuntu22.04. This upgrade requires a limited number of commands, and there are numerous tutorials available on how to accomplish it. We recommend this tutorial.
Opening a terminal
To open a terminal on your operating system, you can follow these steps:
In Windows: Click Start, type PowerShell, and then click Windows PowerShell. Alternatively, if you followed the instructions to install git in BiaPy installation, you should have a terminal called
Git Bashinstalled on your system. To open it, go to the Start menu and search forGit Bash. Click on the application to open it.In macOS: You already have the Bash terminal installed on your system, so you can simply open it. If you have never used it before, you can find more information here.
In Linux: You already have the Bash terminal installed on your system, so you can simply open it. If you have never used it before, you can find more information here.
General usage
Why do network-mounted paths cause issues with Docker or BiaPy GUI on Windows?
When using Docker or the BiaPy GUI on Windows, certain issues may arise with containers accessing network-mounted paths. If you experience problems where specific paths are not detected despite being accessible on your machine, consider using local paths instead to resolve the issue.
Is there a log of my execution when using the GUI?
Yes, every execution of the BiaPy GUI generates a log file named
biapy_%date%-%time%, where%date%and%time%correspond to the numerical date and time of execution. These log files are saved in thelogsfolder within the directory where BiaPy stores user data and configuration. The specific location of this directory varies depending on your operating system and is determined by the platformdirs library.Below are the default locations for each platform:
On macOS:
~/Library/Caches/biapy/
On Windows:
C:\\Users\\<your username>\\AppData\\Local\\biapy\\Cache
On Linux:
~/.cache/biapy/
Train questions
Can I reuse a previously trained model?
Yes, you can reuse that model if you have both its weights (
.pth) and configuration (.yaml) files. Here you have a video explaining how to do it in BiaPy’s GUI:Can I run my worklow on a smaller subset of the input data for just a few epochs, to give an early indication of how things are working?
Regarding the use of less input data, while there is no option to automatically tell BiaPy to use less training data (apart from using a larger validation set), you could simply create a new folder with the subset of the data you wish to use and change the input path so the workflow uses that folder instead of the original.
To get an early indicating of the workflow’s performance, you can
Set the number of epochs to a small value (anything between 1 and 10, for example).
Change the learning rate scheduler to “One cycle”.
Set the learning rate to a higher-than-usual value (something between 0.0005 and 0.001).
The one-cycle learning rate scheduler is a way of very fast training of neural networks using large learning rates, also known as “super-convergence”. The idea behind is to start with a very small learning rate, progressively rise it to a maximum value (which you define) and bring it back down:

One-cycle learning rate scheduler. Over the course of a training run, the learning rate will be inversely scaled from its minimum to its maximum value and then back again, while the inverse will occur with the momentum.
My training is too slow. What should I do?
There are a few things you can do: 1) ensure
TRAIN.EPOCHSandTRAIN.PATIENCEare set as you want ; 2) increaseTRAIN.BATCH_SIZE; 3) If you are not loading all the training data in memory, i.e.DATA.TRAIN.IN_MEMORYisFalse, try to setting it to speed up the training process.Furthermore, if you have more than one GPU you could do the training using a multi-GPU setting. For instance, to use GPU
0and1you could call BiaPy like this:python -u -m torch.distributed.run \ --nproc_per_node=2 \ main.py \ --config XXX \ --result_dir XXX \ --name XXX \ --run_id XXX \ --gpu "cuda:0,1"
nproc_per_nodeneed to be equal to the number of GPUs you are using, 2 in this example.My training got stuck in the first epoch without no error. What should I do?
Probably the problem is the GPU memory. We experienced, in Windows, that even if the GPU memory gets saturated the operating system doesn’t report an out of memory error. Try to decrease the
TRAIN.BATCH_SIZEto1(you can increase the value later progresively) and reduce the network parameters, e.g. by reducingMODEL.FEATURE_MAPSif you are using an U-Net like model. You can also reduce the number of levels, e.g. from[16, 32, 64, 128, 256]to[32, 64, 128].There can be problems with parallel loads in Windows that throw an error as below. To solve that you can set
SYSTEM.NUM_WORKERSto0. In the GUI, you can set it in “general options” window, under “advance options” in the field “Number of workers”.
Test/Inference questions
Test image output is totally black or very bad. No sign of learning seems to be performed. What can I do?
In order to determine if the model’s poor output is a result of incorrect training, it is crucial to first evaluate the training process. One way to do this is to examine the output of the training, specifically the loss and metric values. These values should be decreasing over time, which suggests that the model is learning and improving. Additionally, it is helpful to use the trained model to make predictions on the training data and compare the results to the actual output. This can provide further confirmation that the model has learned from the training data.
Assuming that the training process appears to be correct, the next step is to investigate the test input image and compare it to the images used during training. The test image should be similar in terms of values and range to the images used during training. If there is a significant discrepancy between the test image and the training images in terms of values or range, it could be a contributing factor to the poor output of the model.
In the output a kind of grid or squares are appreciated. What can I do to improve the result?
Sometimes the model’s prediction is worse in the borders of each patch than in the middle. To solve this you can use
DATA.TEST.OVERLAPandDATA.TEST.PADDINGvariables. This last especially is designed to remove that border effect. E.g. ifDATA.PATCH_SIZEselected is(256, 256, 1), try settingDATA.TEST.PADDINGto(32, 32)to remove the jagged prediction effect when reconstructing the final test image.I trained the model and predicted some test data. Now I want to predict more new images, what can I do?
You can disable
TRAIN.ENABLEand enableMODEL.LOAD_CHECKPOINT. Those variables will disable training phase and find and load the training checkpoint respectively. Ensure you use the same job name, i.e.--nameoption when calling BiaPy, so the library can find the checkpoint that was stored in the job’s folder.The test images, and their labels if exist, are large and I have no enough memory to make the inference. What can I do?
You can try setting
TEST.REDUCE_MEMORYwhich will save as much memory as the library can at the price of slow down the inference process.Furthermore, we have an option to use
TEST.BY_CHUNKSoption, which will reconstruct each test image using Zarr/H5 files in order to avoid using a large amount of memory. Also, enablign this option Zarr/H5 files can be used as input, to reduce even more the amount of data loaded in memory, as only the patches being processed are loaded into memory one by one and not the entire image. If you have more that one GPU consider using multi-GPU setting to speed up the process.Warning
Be aware of enabling
TEST.BY_CHUNKS.SAVE_OUT_TIFoption as it will require to load the prediction entirely in order to save it.Is 16-bit precision inference supported?
Yes, 16-bit precision inference is supported. You can enable it by setting
TEST.REDUCE_MEMORYtoTrue, which will generate float16 predictions and help reduce memory usage.How can I reduce memory usage during inference? What is the purpose of ``TEST.REDUCE_MEMORY`` and ``TEST.REUSE_PREDICTIONS``?
If you’re working with large images or limited hardware resources, BiaPy offers two options that can help you manage memory usage and avoid repeating computations:
TEST.REDUCE_MEMORY: This option reduces the amount of memory used during the prediction (inference) step. It does so by simplifying how image patches are processed and by using a more memory-efficient data format. Please note that enabling this option might slightly slow down the inference and reduce precision, but it’s useful when working with large datasets or limited RAM. It is especially helpful whenTEST.BY_CHUNKSis also activated, although in that case only the data format change has an effect.TEST.REUSE_PREDICTIONS: If you’ve already generated predictions for your dataset and saved them to disk, you can enable this option to reuse those saved results instead of re-running the model again. This is particularly useful when testing different post-processing settings without needing to recompute predictions each time, saving time and resources.
Together, these options help make BiaPy more flexible and efficient across different computational setups.
Importing pretrained models
Why are not all the models available in the BioImage Model Zoo for my task compatible with BiaPy?
For technical reasons, BiaPy only supports importing models that were exported in the PyTorch format using a PyTorch state dictionary. This requirement means not all models available in the BioImage Model Zoo will be compatible with BiaPy.
Troubleshooting
General errors
In Linux an error like the following may arise:
OSError: [Errno 24] Too many open files
To sort it out increase the number of open files with the command
ulimit -Sn 10000. You can check the limits typingulimit -a. Add it to your~/.bashrcfile to ensure the change it’s permanent.
In Windows, BiaPy running through Docker may stop with a ``Killed`` error when processing large images
If you are using Docker Desktop on Windows and BiaPy stops during inference or training of large images with an error similar to this one:
/tmp/tmp8z1ohrf7: line 3: 16 Killed python3 -u /installations/BiaPy/main.py --config /BiaPy_files/input.yaml --result_dir /path/to/results --name input_modified --run_id 1 --dist_backend gloo ERROR conda.cli.main_run:execute(127): conda run python3 -u /installations/BiaPy/main.py --config /BiaPy_files/input.yaml --result_dir /path/to/results --name input_modified --run_id 1 --dist_backend gloo failed. (See above for error)
the problem may be caused by the WSL2 resource limits used by Docker rather than by the BiaPy configuration itself. In that case, check the file
C:\Users\<YOUR_USERNAME>\.wslconfigand make sure it allocates enough resources to WSL2. For example:[wsl2] memory=64GB processors=16 swap=32GB
After editing the file, apply the new limits from Windows PowerShell with:
wsl --shutdown
Then restart Docker Desktop and verify the available resources inside the container with:
free -h nprocIf the reported memory or CPU count is much lower than expected, Docker is still running with the previous WSL2 limits.
Graphical User interface (GUI)
In case you have troubles with BiaPy’s GUI, you can find instructions on how to use it in our walkthrough video:
Can’t I resize the GUI?
The GUI is currently not resizable, but you can move it by dragging the logo or the blank area at the top (see red rectangles in the figure):

Running the GUI for the first time:
Windows: once you donwload the Windows binary an error may arise when running it:
Windows protected your PC. This message occurs if an application is unrecognized by Microsoft. In this situation you can click inMore infobutton andRun anyway. These steps are depicted in the figure below:
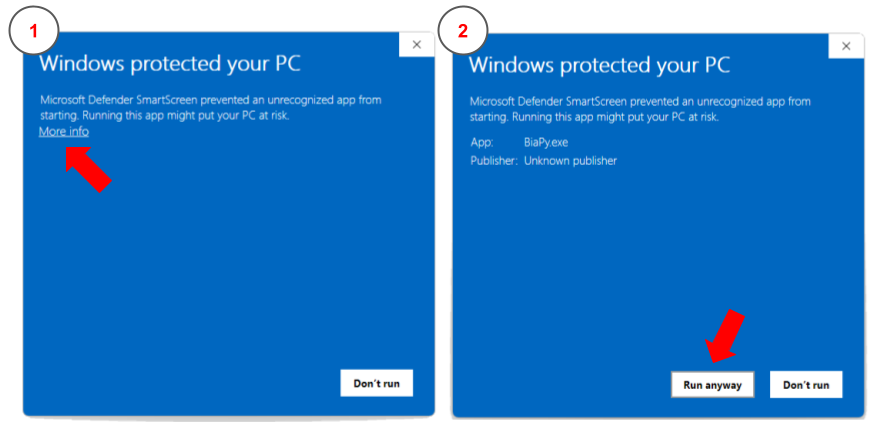
How to bypass the security error message when executing BiaPy app in Windows.
Linux: once you donwload the Linux binary you need to grant execution permission to it by typing the following command in a terminal:
chmod +x BiaPy
macOS: you might experience the following error when open the app for the first time:
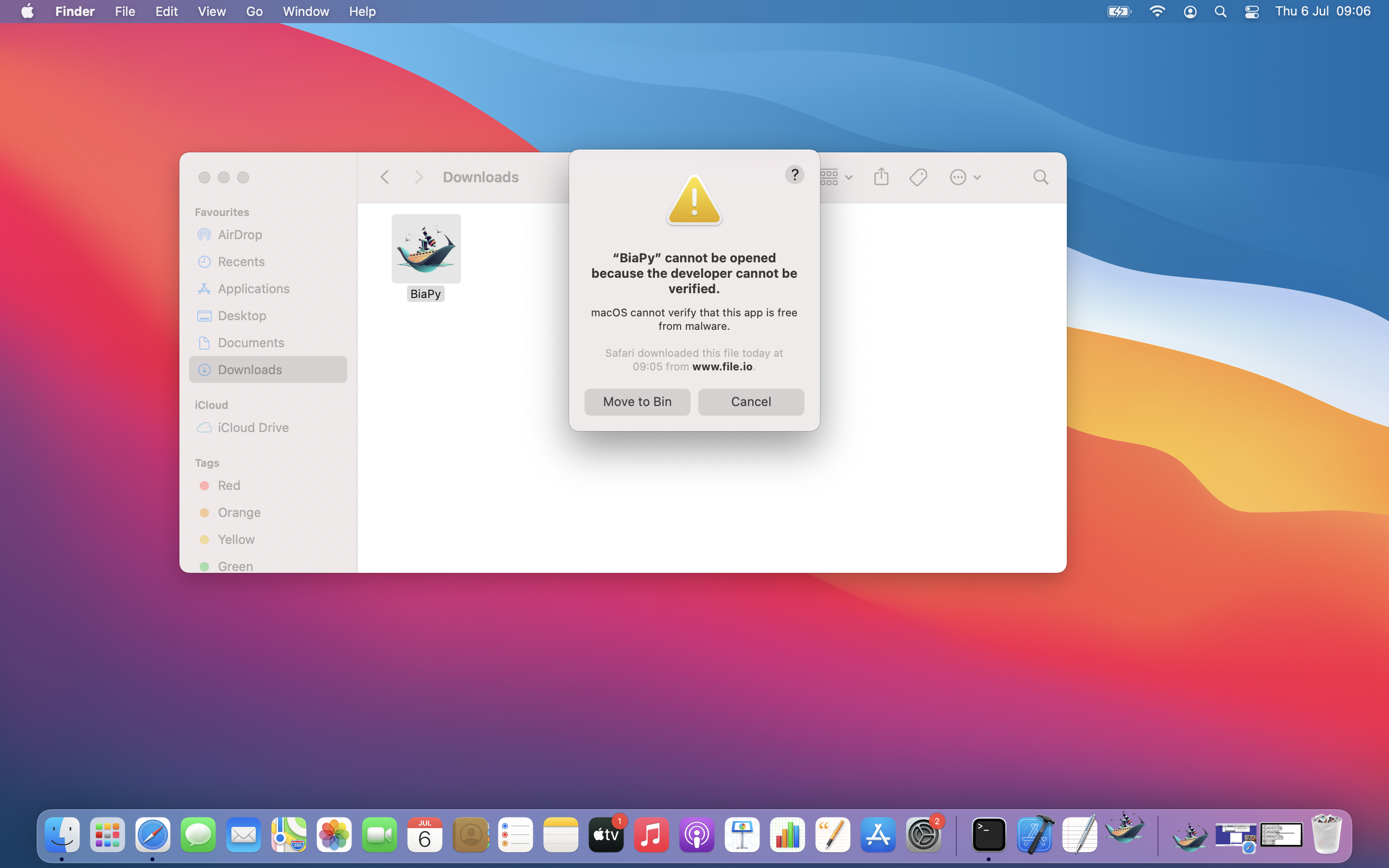
This is a common situation when opening third-party applications. Apple offers different ways of turning BiaPy an authorized application.
In short, you can remove the quarantine attribute through terminal:
xattr -d com.apple.quarantine BiaPy.app
In some versions of macOS, you might also get this other security error when trying to execute the BiaPy application for the first time:
This is a known issue that can be easily bypassed by following these instructions.
When running BiaPy from the GUI on Windows, none of the Docker containers start and you get an error like this:
docker.errors.APIError: 400 Client Error for http+docker://localnpipe/v1.49/containers/create: Bad Request ("range of CPUs is from 0.01 to 2.00, as there are only 2 CPUs available")
This usually means that the value configured in the GUI for Number of CPUs is higher than the number of CPUs Docker is exposing on that machine. In the GUI, go to Advanced options and reduce Number of CPUs to a value Docker accepts, for example
1or2.This workaround was confirmed for CPU execution on an older Windows workstation where Docker only detected two CPUs, even though the machine had more physical cores available.
When running BiaPy, as it is starting and after downloading you may get the following error:
GPU error docker.errors.APIError: 500 Server Error for http+docker://localhost/v1.46/containers/9ff69069d7627753045d46f9bb4246f56024a937b48746e0708d3499c9f852a5/start: Internal Server Error ("could not select device driver "" with capabilities: [[gpu]]")
This suggest that the NVIDIA GPU compatibility was not correctly set up (probably the nvidia container toolkit). Find the following useful links describing a few steps you can follow: https://github.com/NVIDIA/nvidia-docker/issues/1034 and https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/1.13.5/install-guide.html
Limitations
Through the graphical user interface the multi-GPU is not supported.